
In December 2022, our research director Sabri Skhiri travelled to Osaka to attend IEEE Big Data 2022, a conference that has established itself as the top tier research conference in Big Data. He sums up the main trends, and shares his favourite talks and papers below:
Abstract
I have attended the IEEE Big Data for 8 years in a row. That is a fantastic conference for me at the edge of infrastructure optimization, distributed computing, machine learning and data management. The call for papers mentioned the main topics: Big Data Science and Foundations, Big Data Infrastructure, Big Data Management, Big Data Search and Mining, Big Data Learning and Analytics, Big Data Applications, Data ecosystem. In addition, you need to consider the 30 workshops going from legal tech to data science in healthcare, ethical AI, cybersecurity, trust and privacy, ML for sciences, to name the biggest (and stream processing and real time analytics of course).
What I personally like in this conference is the variety and the global overview it gives on the state of the art. I listened to talks on privacy, fraud detection at Rakuten, BNP and at the Indian trade office, data management of feature stores, how GPUs can make feature engineering pipelines at Alibaba more efficient, Graph Knowledge Streaming, graph anonymization, federated learning implementation on serverless infrastructure with Stragglers management, etc.
The Big Trends
Highlight: Expert level deep learning, Bert at all sauces, Graph almost in every track, awareness of the trust-tranparency-privacy challenge and first solutions
Expert level deep learning: Most of the talk about deep learning was relatively good. In the histogram of keyword occurrences, I can tell you that these words are clearly above the others: contrastive learning, triplet loss attention mechanism and language model. A bit less RL but still. The interesting point here is that all these talks were cleverly adapting these concepts for their one use case. As a result, I saw the conference as a collection of good recipes for adapting these generic concept to a particular case.
Bert at all sauces: This is clearly a trend. Bert is used for anything containing a sequence of terms, for example to identify malicious codes in cybersecurity or even to encode a sequence of events that lead to a process that can in turn emit events in SIEM. In this case, the events and the processes are the words and a normal log is a sentence. I even saw Bert used for modelling sequences of user behaviour.
Graph in almost every track: In every session, there was a paper about graphs, such as knowledge graphs, graph streaming for temporal graphs, graph embeddings applied on various use cases such as frauds, anomaly detection, user behaviour analysis, etc.
Awareness of the trust-tranparency-privacy challenge and first solutions: This is clearly something that we can observe in other ML conferences. Trust, privacy and explainability are becoming the new black. Here, there was even a Responsible AI workshop entirely dedicated to this question.
Beside these trends, there were a lot of talks about infrastructure, such as serverless computing, usage of K8S, GPU cluster optimizations, etc. It was good to see that nobody talks about the grid anymore!
The Keynotes Speeches
A Vision for Data Alignment and Integration in Data Lakes
In this talk, Renee Miller gave an exhaustive view of data lake integration techniques. The idea is that a data lake is basically the area where all data are automatically extracted. Therefore, looking for a data set given a data science task is not trivial and requires finding sources and merging them.
DATA LAKES
The vision of the data lake as presented was very basic; it was still based on the schema inference mechanism and with a pure self-service orientation.
Note of the writer: this is the trend we are observing on the market heavily pushed by Gartner. This is the evolution of data governance where the Enterprise data Model is expressed as a knowledge graph. The project Tetrat KG3D of the KU Leuven goes in this direction by leveraging this knowledge graph for data integration.
The first generation of data lakes had this famous assumption schema on read. Basically, you write everything as a flat file and the reader maps a schema on top. Here, prof. Miller proposes a slightly different configuration where all the data are blindly written on the lake (without any semantic structure) and the lake management tries to define schemas and relationships. This is quite far from the reality, but at least it gives a common foundation for the research.
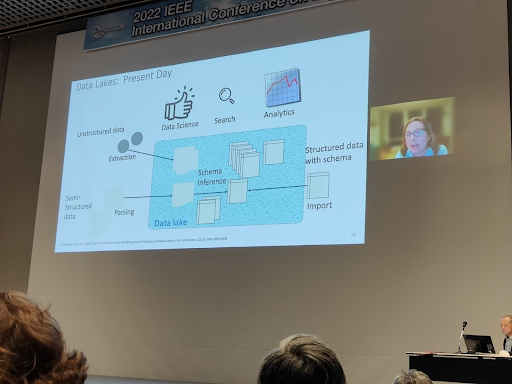
In most of the data lake management we have been working for, we had:
- A clear source schema (that is kept for loading data into the lake)
- A strong data governance in place for qualifying relationships if they exist
In this context, the new challenge is metadata discovery because most of the data was extracted automatically. This research looks like the research direction of Prof. Felix Neumann at the HPI (Berlin) where his entire line of research was about generating metadata for individual tables and finding inclusion and functional dependencies.
Data set search
- Using meta data: Google data set search
- Using data
Metadata discovery
- Data lake exploration (Ouellette 21, Nargessian 20)
- Semantic type discovery
- Harmonization: encourage reuse of metadata and data definition (this is what is called data governance in the industry)

Table join example: using a table query and finding where this query can be joined. For this problem, we have 2 main options in the state of the art:
- LSH ensemble
- Josie, that works with massive inverted index, with an optimized cost-based search model
The second type of query is “does my table generalize ?”
In this case, this is rather a union search among the other tables from the lake.
This means that we need to be able to identify similar columns in other tables:
- using word embedding of the vocabulary column
- using knowledge graph or ontology

VISION OF DATA LAKE INTEGRATION
Good practice
- Well-designed data from data management text book (Codd/date)
- Common web data: use domain specific collaboration ontologies, KB
- NLP: text embedding or entity recognition
Recovering semantics from relationships: without any additional information, tables look unionable (see picture):
- KB: provide high precision
- Data lake: try to understand if relationships in different tables are the same
- Language model where you learn contextual information
NETWORK SCIENCE (GRAPH) VIEW OF DATA LAKES
Can we see data lakes as a graph? Can we apply graph abstraction on data lakes?
In the case where value can have multiple meaning, can we use the graph for disambiguate ?
DomainNet is an example of graph theory applied on this data lake disambiguation.
The intuition: a homograph likely co-occurs with a set of values that do not co-occur frequently. If we use the co-occurrence intuition, can we assign a homograph score to each data value? The betweenness centrality can be used to define if a value corresponds to a homograph. The number of homograph negatively impacts semantic relationship extraction methods.
The closing note was: Let’s consider data lakes as graphs! This is the trend we are observing on the market heavily pushed by Gartner. This is the evolution of data governance, where the Enterprise data model is expressed as a knowledge graph. The project Tetrat KG3D of the KU Leuven goes in this direction by leveraging this knowledge graph for data integration.
Favourite Talks
Improving Representation Learning for Session-based Recommendation
Session-based recommendation: a user session is a sequence of user actions, and the aim is to predict the next action. The key element here is to capture intra and extra session relationships. Usually, they capture the co-occurrence of similar action patterns among sessions. However, the usage of co-occurrence often leads to wrong signals. The contribution here is to automatically learn signals in different sessions and to build a graph of co-occurrence. This graph is used for defining the importance of these occurrences.
The second steps was to learn session representation using contrastive learning. In this case, the session augmentation is made by adding noise to the current session. They do that at the item level of a session, add a random item, applying a dropout. In addition, they use a masked approach for the resulting session.
I liked the method because it is relatively simple and pragmatic. The exhaustive experimentation showed an average 12% improvement. But it seems that the paper was already published in a different form.
FedLesScan: Mitigating Stragglers in Serverless Federated Learning
This was a talk by TU Munich and Huawei.
The first part was a short introduction to serverless computing and federated learning. The FaaS was presented as the latest evolution of the distributed computing and infrastructure management (I disagree on that claim).
Then, the speaker mentioned the stragglers problem, where you have a client (linked to function in the serverless configuration) that significantly increases its local training time.
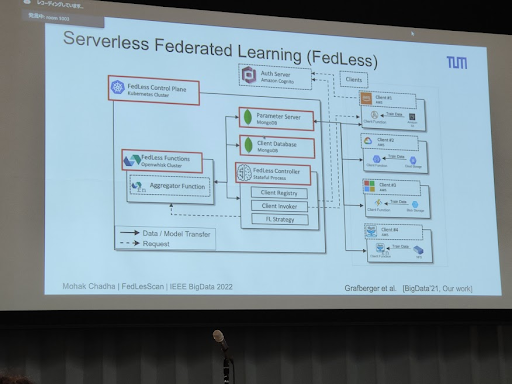
There are server strategies that can be applied:
- Persistent communication links
- Increase resource utilization
- Increase training time
Contribution: cluster-based approach.
- Intelligent client selection: DB scan for client selection:
- Tier-1 client not participated before
- Reliable client
- Recently experienced slow behaviour
- A staleness-aware aggregation scheme to mitigate slow model updates and avoid wasted contribution of clients.
I liked the talk because it is at the edge between infrastructure management, architecture, machine learning. Basically what we do at customers!
Preprint paper here.
Adaptive Attacks and Targeted Fingerprinting of Relational Data
Digital fingerprinting: identify the owner, identify the recipient. It started with media and later moved to text and relational data. The idea is to link a content with an owner digitally. This is done with a pseudo random modification of the data. The idea is that this modification is associated to a secret key. This fingerprint is supposed to be able to trace uniquely each row (the recipient) to the owner. In this context, an attacker will try to remove the fingerprint by either selecting features or removing columns.
Challenge data utility Vs robustness:
- Utility: direct on the start measure or indirectly on the impact on the task.
- Robustness: resilience against modification. Fingerprint is robust if it cannot be removed without decreasing utility. How to evaluate the cost of attack?
Targeted attack:
The attack aims at either selecting features or removing columns in order to remove the fingerprint.
Defence:
- Maximize the data utility loss caused by the fingerprint
- Maximize robustness of the scheme
- Minimize attacker’s utility loss
I liked the talk for the rigorous methodology: (1) definition of the threat, (2) modelisation of the existing solutions, attack and measure to evaluate the attack, (3) defence mechanisms and (4) evaluation. Voilà. Straight to the point.
Protein-Protein Interactions (PPIs) Extraction from Biomedical Literature using Attention-based Relational Context Information
I liked this talk because it shows that a machine learning model can capture complex relationships using literature, in this case medical literature. This is a good foundational model to explore how we could retrieve semantic relationships from texts.
The authors developed a transformer based relation prediction method within an entity relational context. First, during the curation phase, they expand the label “positive relationships” to “enzyme” or “structural”. This produces a finer grained semantic relationship between proteins. They use BERT for the identification of the relationships. They consider the entities as a token in BERT. By the way, they consider the entity extraction already done; that means that you know upfront for which tokens you are looking for a relationship. The entity extraction is the subject of the previous paper of the author. For the relation representation, they look at the last layer of BERT to extract the attention probabilities of a token. The intuition is that BERT extracts the contextual information of the relationship between two entities.
In terms of future works, they are working on more granularity of the type classification and the identification of relationships that spans over two or multiple sentences.