
Abstract
On the website, we can read this:
PETs Summit Europe heads to London from 28 February to 1 March with a focus on strategy, use cases and steps for implementing and adopting privacy-enhancing technologies. Across two days, hear from, network with and benchmark against industry peers and a leading speaker faculty of early adopters, innovators and drivers. Explore how PETs enable collaboration and sharing of sensitive data in a privacy-preserving manner – and the unprecedented opportunities they bring.
- Key highlights from 2023 include:
- Building and tracking the business case for PETs adoption with Banque Raiffeisen, Aston Martin and LG Technology Ventures.
- Fexco, Danaher Life Sciences and BT discussing how PETs can support navigating the globally fragmented data and privacy landscape.
- Identifying the correct PET(s) for the challenge with KU Leuven, What Works for Children’s Social Care and Swiss Post.
- How Copper.Co, Hastings Direct and Eurostat are incorporating PETs into a broader data strategy.
- Industry-focused case studies and challenge-specific roundtable discussions.
Tags: <privacy, synthetic data, encryption, sharing data, >
The Big Trends
Innovating and creating value from data needs
In this kind of conference, you can cross paths with lawyers, tech vendors, heads of analytics/AI and even regulators! All these people speak about GDPR, anonymisation, ethics, cross-border data exchanges, data value management, data governance… you name it. As you can guess, these were the happiest days of the year for me! (EDIT: The happiest days were a few days after we finalised the Responsible AI service offer).
This year, the main learning from the conference is that deploying a PET requires just a bit of understanding…
- Understanding the value: the value of unlocking business opportunities and business cases, but also the counterfactual value, as the value of not going into a data breach or not having a lawsuit.
- Understanding the regulatory context: the GDPR, the AI Act, the Data Act, the Data Governance Act, the recommendations on data transfer and cross-border data sharing,… even laws in China and the US.
- Understanding the ins and outs of data sharing: What does ‘data sharing’ mean? What is a processor, a controller? What is further processing? Can I share data privately, and If I can, what does that involve? What technical and legal constraints apply?
- Understanding how data governance is involved to ensure that all processes, roles and responsibilities are aligned.
- Understanding the risks: What is a risk in the fields of data usage or data sharing? Is it quantifiable? What proxy measures can be taken to assess the risk? Should I evaluate the risk/benefit balance? Most of the time, understanding the risk also means a deep understanding of the technology.
- Understanding the PETs offers, tradeoffs, pros and cons: FHE, trusted environment, differential security/ privacy, synthetic data generation, pseudonymization. What would be the pros and cons between multi-party computation and federated learning?
- Understanding the impact on AI: you should be able to understand what impact the PET you choose will have on your AI models. On the one hand, using synthetic data (created data that mirrors the balance and composition of real data) is good for explainability and fairness. However, its privacy risk is not standard (as you still risk disclosure of real data attributes). On the other hand, encrypting your data is bad for fairness and data cleaning. For instance, can we use deep learning with FHE? Not really. For the moment, it only works on linear computation.
You’ve got the idea: Deploying this kind of tech remains a challenge since it requires a lot of different profiles in the room. Incidentally, a few talks during the conference touched on the subject of putting together a multidisciplinary A-team of experts to tackle this type of project.
The last trend of the conference was collaborative computing as a way for organisations to collaborate within an ecosystem to share their data, while not being allowed to see the data from the others. PETs can meet this challenge.
Interestingly, there was no mention of data value management. The speakers talked a lot about PET and value enablers but not really about putting in place an end-to-end strategy to link data to the value they generate. Yet, this strategy has become the gold standard in the market within the last two years.
Key takeaways:
- The market needs regulatory guidance. For instance, there is no standard way to evaluate the privacy risk. Synthetic data, differential privacy and FHE are highly complex technologies. The regulator cannot leave companies to fend for themselves in the face of such technological complexity. It must put in place more measures and guidance on the use of these technologies than the law currently provides.
- In the meantime, a good practice would be to try to find a tradeoff between technical complexity and liability (demonstrate that you have made an effort without necessarily being at the edge of the tech, but at the same time, try to avoid breaches).
- The sales pitch is important: do not talk about PET nor data governance. Instead, talk about new revenue streams, business strategy, and data strategy. PET/data gov will come naturally from there.
- Deploying PETs requires many different profiles (data governors, lawyers, techies, business representatives).
- The encryption families of PETs do not seem really adapted to deep learning and complex machine learning models. In addition, if you encrypt, you lose the ability to evaluate fairness, and you miss the precious work done manually by data scientists when they cure data.
- The data governance practice in place should include recommendations and guidelines related to PETS.
Regarding regulatory guidance, the Information Commissioner’s Office (ICO), IEEE and the Royal Society work actively to build expert working groups to provide clearer recommendations, including tech-related recommendations.
Favourite Talks
PETs and Synthetic Data: A Regulatory Perspective and Financial Services Case Study
Abstract
Data has the power to drive advancements in the use of artificial intelligence (AI) and machine learning (ML), which could unlock significant value in financial markets and lead to better outcomes for consumers, firms and the wider economy. However, in order to protect consumer privacy, it is important that data sharing occurs under certain conditions and with an appropriate legal basis. In March 2022, the Financial Conduct Authority (FCA) published a Call for Input to explore the market maturity of synthetic data and industry views of the potential for synthetic data to expand data-sharing opportunities in financial services. This session will explore the key findings from the Call for Input and discuss the FCA’s broader PETs programme.
- Quality: replicating bias in synthetic data. (NDLR: we have noticed in our research that outliers vanish or amplify during the synthetic data generation).
- Validation: no clear benchmark on what are good performances for generation.
- Ethics: What about consumer consent? What about the ethics of the decision made with synthetic data?
- Privacy: privacy leakage from synthetic data generators. The latest state of the art and risk that it entails.
Panel: Building and tracking the business case for PETs adoption
Abstract
Privacy-enhancing technologies have been demonstrated as technically effective – but that is not enough. Their implementation requires resource allocation, both in terms of acquiring the technology and subsequently monitoring it. The talk discussed :
- Establishing how PETs can deliver additional business value through unlocking previously inaccessible data
- Practical first-hand examples successfully identifying relevant use cases, establishing proof of concept and seeing tangible return upon implementation
- Learning how to quantifiably measure that return upon implementation and assess the need for potential amendments or new areas of application
This was one of the first panels of the conference. As they opened the party, they listed the set of PETs technologies: FHE (fully homomorphic encryption), MPC (multi-party computation), FE (functional encryption), trusted environment, differential security/ privacy, synthetic data generation, and pseudonymization.
NLDR: if you need a crash course on the different types of encryption (MPC, FHE, FD), here is an interesting link.
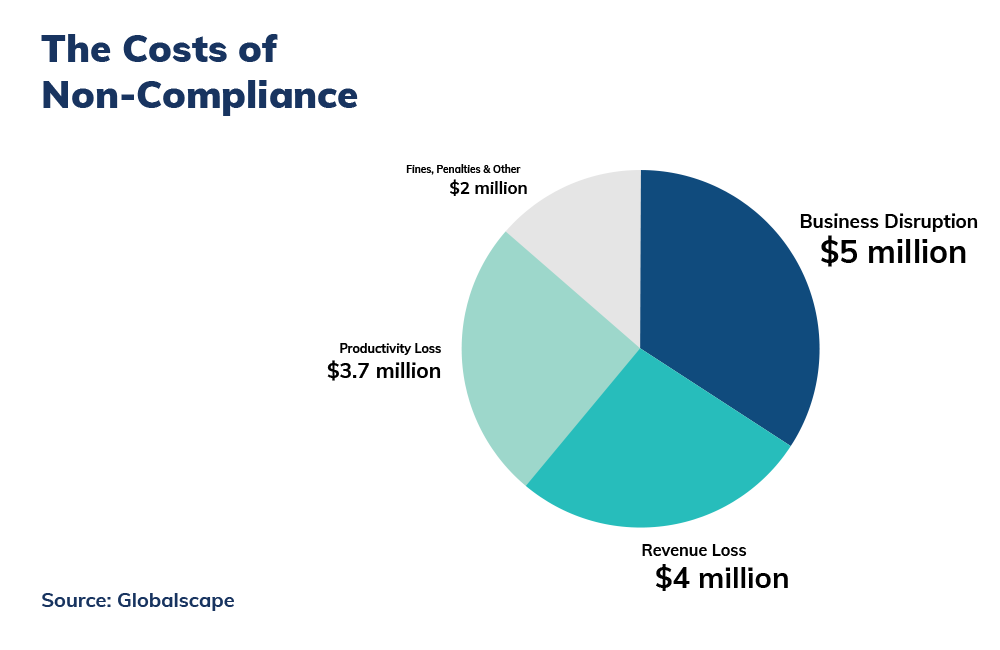
The second focus during this panel discussion was the marketing narrative to sell or deploy PETs and its past developments, starting with the compliance story, the cost of non-compliance, the fear of fines, followed by data sharing and business enablement. The idea was that innovation and value creation should have been a consequence of sharing data with daughter companies and within the business’s ecosystem. The narrative today puts value creation and innovation freedom at the core.
{kind=link}
In addition, PETs technologies should not be visible to the data user and the complexity of the underlying tech should not be a showstopper.
The data-sharing story involves a challenge I mentioned above: a company wants to share data with other organisations, but should not be able to see the data from the others. That is where federated learning and MPC play an important role. A panellist noted that PETs could be combined. In this case, combining MPC and differential privacy could allow for « collaborative computing » where a business ecosystem could collaborate on a common computing function without sharing data.
NDLR: This is an interesting point at the edge between technical features and legal requirements. MPC guarantees that you can have common processing with 3rd parties without any party having access to the data from others. However, from a legal viewpoint, if your data set contains personal and sensitive data, and if you do not have any legal basis for processing them, you can simply not use them. As a result, you can apply differential privacy to anonymise them and then, still use MPC in order to avoid sharing anything with other parties, while still collaborating on common processing.
Another important message given during the panel was about the need to find the right balance between business enablement and regulation. Every data-driven business case must go through the regulation firewall. (NDLR: The data governance process ensures that you can get the correct legal basis to access the entire data set). The PETs allow for finding a balance between legal requirements and business incentives.
There was an interesting claim: « The impact of the cloud-trusted environment (where your VM is basically a fortress where the memory, storage and network are encrypted) is significant since it can resolve up to 95% of your need. NDLR: not sure it is true. If you speak about sensitive data that you need to process in a secure environment, protected from any hacks, that is fine. However, for privacy-related data, it does not change anything on data sharing or any processing out of the initial purposes.
Who are the typical buyers of this kind of tech? CISO used to be. Now it is CISO, legal compliance bodies, CTO/CIO, CDO. That also means that a lot of people with very different profiles are involved in the decision process. That is why we need a pluri-disciplinary team to support the project (NDLR: another talk presents the typical team).
As a final note, the panel discussed a last interesting question: privacy & confidentiality. With the rise of data privacy regulations and the fear of fines, RegTech (regulatory technologies) have been designed to ensure legal compliance. However, confidentiality is also an essential matter for most of the companies dealing with data, and this should be driving the first business cases. NDLR: Indeed, there is a significant focus on privacy, while confidentiality is equally important. Notably in some customer domains where there is not especially a lot of personal data, such as public transport, energy or defence.
NDLR: I had a question about using the FHE scheme in deep learning. Here are my first conclusions. First, FHE has been designed for linear operations, but for non-linear and deep learning operations, you need a specific subtype of FHE. Although using such a subtype seems feasible, it does not seem obvious to run FHE for a fair amount of data in a training process. This paper shows how we can achieve reasonable results but at a certain price of effort. Finally, if your model has been trained on encrypted data, the application of the model should also be made on encrypted data. This makes this process highly costly from a computational viewpoint. You guessed it; I am not a big fan of this technology.